
|
|

|
| Capturing and Exploiting Semantic Relationships for Information and Knowledge Management | |
Description
Trellis is an interactive web-based application for argumentation and decision-making. Using Trellis, uses can come to individual and collaborative conclusions on virtually any topic, from scientific discourse to political and policy views to deciding which product to purcase or select the place to stay on a vacation.
The key innovative ideas behind our approach are:
- Supporting users to create knowledge "snippets" (microcontent) from the original sources as well as from other microcontent. The key is to capture how the user progressively generates new knowledge that results in added value to the original raw information sources. Our goal is to support users to highlight key salient information from large reports and documents, to add new knowledge fragments based on their analysis and integration of existing information, and to finally create semi-formal fragments.
- Capturing and exploiting interrelations between contributor-generated public semantic annotation of information. As part of their analysis, users are given the opportunity to annotate raw information sources with knowledge about the source's quality and relevance to given topics. The users are also encouraged to enter their analysis in a form which facilitates retireval of relevant additional analyses, microcontent, and web sources. The tool provides incremental payoff to the user -- the more the user annotates and helps the system understand the analysis, the more help the system can render.
- Extensible semantic markup of information items and their relationships. Users will be able to draw from a core semantic markup language that will contain a basic domain-independent vocabulary to formulate annotations. They will also be able to extend this core language with additional terminology useful in their particular domain. Using this language, users will be able to annotate not only the information items themselves, but they will also be able to annotate the relationships among them, which will enable them to qualify and describe interdependencies between different information sources and how they relate to a new conclusion or assessment added by the developer. In essence, links between the information items will be first class citizens in the knowledge base.
Below is a diagram of the current Trellis architecture. A User typically starts searching the Web for a certain document, or indicating a pointer to a specific Web resource that contains useful information. Each is considered an information item. Information items may include raw information sources (an image, a text document, a video, etc.) as well as products of previous analysis (by the user or by other users.) All the information items are in some sense the knowledge base that Trellis operates on, and we refer to it as the Semantically Marked Information Base, or SMIB. We refer to an information item as an EI2 (Extended Information Items).
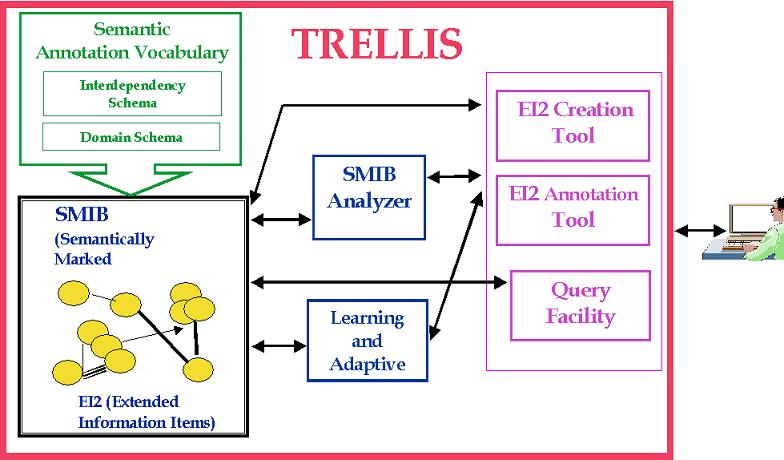
Users extend the SMIB using two tools: the Annotation Tool and the Creation Tool. They can use the EI2 Annotation Tool to add semantic annotations to an EI2 to describe its contents and to relate them to other EI2. For example, an EI2 may be annotated as containing a map, or an interesting event. The Annotation tool can also be used to relate EI2. The tool will provide an editor with a set of connectors. An example is a connector to denote that two EI2s are contradictory. This way, the user may link an EI2 that contains a description of a product as having a tag price of $20 to another EI2 that has the same product with a price of $25.
The Annotation tool draws on a library of semantic annotations and connectors that will be based on a core domain-independent language defined by the Semantic Annotation Vocabulary. An Interdependency Schema defines a vocabulary for connectors based on a variety of dimensions: pertinence, reliability, credibility, structural (x is example of y, x is part of y, x describes y, etc.) causality (x1 x2...xn contribute to y, x1 x2...xn indicate y, etc.) temporal ordering (x before y, x after y, x simultaneous with y, etc.), argumentation (x may be reason for y, x supports y, etc.). The Domain Schema contains a core vocabulary to annotate the content of documents that extends the Interdependency Schema with domain terms. Our plan is that Trellis will provide a core vocabulary, and users will be able to extend it with additional terms.
The Creation Tool enables users to create new EI2. For example, a user may create an EI2 as an assessment that he or she formulates based on existing EI2. If a combination of some subparts of EI2 lets a user conclude or decide on some definition, then the subparts can be captured into a new Information Item, that drops all other irrelevant parts of the original EI2. A new EI2 can be added by extracting or summarizing some of the previous results.
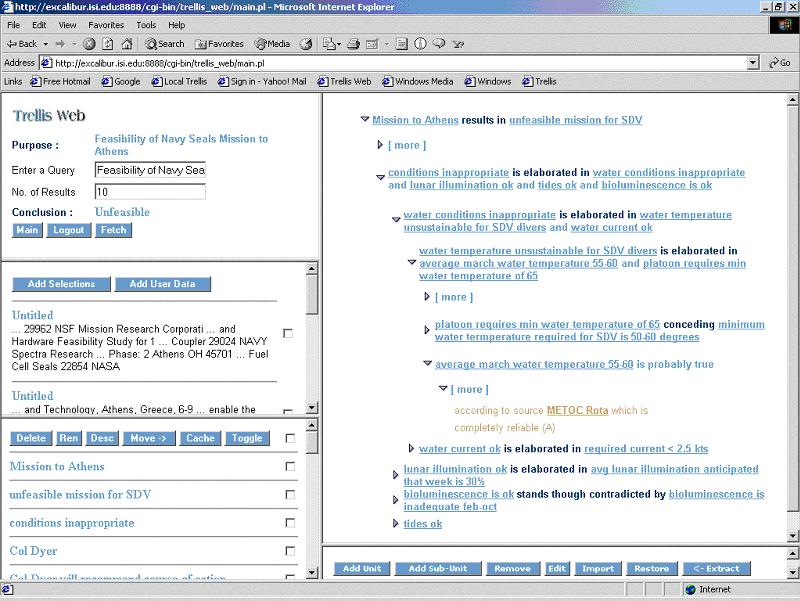
Below is a snapshot of the current user interface of Trellis. In this case, a user is using Trellis to decide whether a mission to take Navy SEALs to Athens is feasible. Given the Web sources consulted and the indicated capabilities of the SEAL team (shown on the left), the user has entered the rationale for deciding that the operation is not feasible.
We plan to extend Trellis with learning and adaptive techniques in order to offer to the user improved and extended capabilities over time. As users annotate more EI2 and create new EI2 that capture their analysis, Trellis will be able to exploit this information and become increasingly more proactive. We also plan to add a Query Facility that will allow users to search the SMIB based on the semantic annotations of the EI2. It will include a structured editor to guide users to formulate queries using the semantic annotation vocabulary defined in the schemas.
In summary, Trellis provides users with tools that enable them to specify information in increasingly more structured form, and to specify semantic annotations that can be exploited for processing and integration of separate information items.